
标准偏差和标准误差
介绍
标准 d eviation(SD) 和 小号 TANDARD Ë RROR (SE) 看似相似的术语;然而,它们在概念上是如此多样化,以至于它们在统计学文献中几乎可以互换使用。这两个术语通常都以正负号(+/-)开头,这表示它们定义了对称值或表示了一系列值。总是,两个术语都以一组测量值的平均值(平均值)出现。
有趣的是,SE与标准,错误或科学数据的通信无关。
详细了解SD和SE的起源和解释将揭示,为什么专业统计学家和那些使用它的人都倾向于犯错误。
标准差(SD)
SD是一个 描述的 描述分布传播的统计数据。作为度量标准,在数据正常分布时非常有用。但是,当数据高度偏斜或双峰时,它不太有用,因为它没有很好地描述分布的形状。通常,我们在报告样本的特征时使用SD,因为我们打算这样做 描述 数据在均值附近变化了多少。用于描述数据传播的其他有用统计数据是四分位数范围,第25和第75百分位数以及数据范围。
方差是一个 描述的 统计也是,它被定义为标准差的平方。在描述结果时通常不会报告,但它是一个更加数学上易处理的公式(也就是偏差平方和)并在统计计算中起作用。
例如,如果我们有两个统计数据 P & Q 已知方差 VAR (P) & VAR (Q) ,然后是总和的方差 P + Q 等于方差的总和: VAR (P)+ VAR (Q) 。现在很明显为什么统计学家喜欢谈论差异。
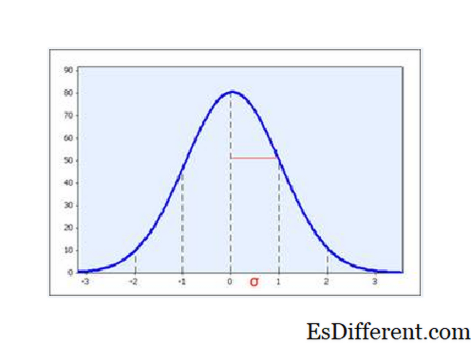
但标准偏差对于传播具有重要意义,特别是当数据是正态分布时:区间平均值 +/- 1 SD 可以预期捕获2/3的样本,并且间隔意味着 + - 2 SD 可以预期捕获95%的样本。
SD提供了对问题的个体回答在多大程度上与均值“变化”或“偏离”的指示。 SD告诉研究人员如何将响应分散开来 - 它们是集中在均值周围还是分散在远处?您的所有受访者是否都在您的规模中考虑您的产品,或者是否批准了某些产品并且有些人不同意?
考虑一个实验,要求受访者按照5分制对一系列属性的产品进行评分。一组十个受访者(下面标有'A'到'J')的“物有所值”的平均值为3.2,标准差为0.4,“产品可靠性”的平均值为3.4,标准差为2.1。
乍一看(仅查看方法),可靠性似乎高于价值。但可靠性较高的SD可能表明(如下面的分布所示)响应是非常两极化的,大多数受访者没有可靠性问题(将属性评为“5”),但是一个较小但很重要的受访者群体可靠性问题并将属性评为“1”。仅仅观察平均值只能说明故事的一部分,然而,这往往是研究人员关注的焦点。回应的分布非常重要,SD可以提供有价值的描述性衡量标准。
| 回答者 | 物有所值 | 产品可靠性 |
| 一个 | 3 | 1 |
| 乙 | 3 | 1 |
| C | 3 | 1 |
| d | 3 | 1 |
| Ë | 4 | 5 |
| F | 4 | 5 |
| G | 3 | 5 |
| H | 3 | 5 |
| 一世 | 3 | 5 |
| Ĵ | 3 | 5 |
| 意思 | 3.2 | 3.4 |
| 标准。开发。 | 0.4 | 2.1 |
第一次调查:受访者对产品的评分为5分
对5分评定量表的两种非常不同的响应分布可以产生相同的均值。请考虑以下示例,显示两个不同评级的响应值。
在第一个例子中(等级“A”),SD为零,因为所有响应都是平均值。个人反应并没有完全偏离平均值。
在评级“B”中,即使组平均值与第一个分布相同(3.0),标准偏差也更高。 1.15的标准偏差表明,平均值*的个体反应距平均值略多于1个点。
| 回答者 | 评级“A” | 评级“B” |
| 一个 | 3 | 1 |
| 乙 | 3 | 2 |
| C | 3 | 2 |
| d | 3 | 3 |
| Ë | 3 | 3 |
| F | 3 | 3 |
| G | 3 | 3 |
| H | 3 | 4 |
| 一世 | 3 | 4 |
| Ĵ | 3 | 5 |
| 意思 | 3.0 | 3.0 |
| 标准。开发。 | 0.00 | 1.15 |
第二次调查:受访者对产品的评分为5分
查看SD的另一种方法是将分布绘制为响应的直方图。具有低SD的分布将显示为高的窄形状,而大SD将由更宽的形状指示。
SD通常不表示“对或错”或“更好或更差” - 较低的SD不一定是更理想的。它纯粹用作描述性统计。它描述了与平均值相关的分布。
Ť 与SD有关的技术免责声明
将SD视为“平均偏差”,是从概念上理解其意义的一种极好方式。但是,它实际上并不是以平均值计算的(如果是,我们称之为“平均偏差”)。相反,它是标准化的,是一种使用平方和来计算价值的复杂方法。
出于实际目的,计算并不重要。大多数制表程序,电子表格或其他数据管理工具都会为您计算SD。更重要的是要了解统计数据传达的内容。
标准错误
标准错误是 推理 在比较人群中的样本均值(平均值)时使用的统计量。这是一个衡量标准 精确 样本均值。样本均值是从具有基础分布的数据派生的统计量。我们可以用与数据相同的方式对其进行可视化,因为我们已经执行了单个实验并且只有一个值。统计理论告诉我们,样本均值(对于一个大的,非常大的样本和一些规律性条件)大致是正态分布的。这种正态分布的标准偏差就是我们所说的标准误差。

当我们想要比较治疗A与治疗B的双样本实验的结果平均值时,我们需要估计我们测量平均值的准确程度。
实际上,我们对于我们如何精确地测量两种方法之间的差异感兴趣。我们将此度量称为差异的标准误差。您可能不会惊讶地发现样本均值的差异的标准误差是平均值的标准误差的函数:


,其中n是数据点的数量。
请注意,标准误差取决于两个组成部分:样品的标准偏差和样品的大小 ñ 。这具有直观意义:样本的标准偏差越大,我们对真实均值的估计就越不精确。
此外,样本量越大,我们对人口的信息越多,我们就可以更精确地估计真实均值。
SE表示平均值的可靠性。小SE表示样本均值是对实际总体均值的更准确反映。较大的样本量通常会导致较小的SE(而SD不受样本大小的直接影响)。
大多数调查研究涉及从人口中抽取样本。然后,我们从该样本的结果中推断出人口。如果抽取第二个样本,结果可能获胜,与第一个样本完全匹配。如果一个样本的评级属性的平均值为3.2,则对于相同大小的第二个样本,它可能为3.4。如果我们要从我们的人口中抽取无数个样本(大小相等),我们可以将观察到的均值显示为分布。然后我们可以计算所有样本均值的平均值。这个平均值等于真实的人口平均值。我们还可以计算样本均值分布的SD。样本均值分布的SD是每个样本均值的SE。
因此,我们有最重要的观察: SE是人口均值的SD。
| 样品 | 意思 |
| 1 | 3.2 |
| 第2 | 3.4 |
| 第3 | 3.3 |
| 第四 | 3.2 |
| 第5 | 3.1 |
| …. | …. |
| …. | …. |
| …. | …. |
| …. | …. |
| …. | …. |
| 意思 | 3.3 |
| 标准。开发。 | 0.13 |
表格说明了SD和SE之间的关系
现在很清楚,如果这个分布的SD有助于我们理解样本均值与真实总体均值的距离,那么我们可以用它来理解任何单个样本均值与真实均值的准确程度。这是SE的精髓。
实际上,我们只从我们的人口中抽取了一个样本,但是我们可以使用这个结果来估计我们观察到的样本均值的可靠性。
实际上,SE告诉我们,我们可以95%确信我们观察到的样本平均值大约为2(实际上是1.96)来自总体均值的标准误差。
下表显示了我们用于研究的第一个(也是唯一的)样本的响应分布。相对较小的0.13的SE表明我们的平均值与我们总体人口的真实平均值相对接近。我们的平均值的误差范围(95%置信度)是(大约)该值的两倍(+/- 0.26),告诉我们真实均值最有可能在2.94和3.46之间。
| 回答者 | 评分 |
| 一个 | 3 |
| 乙 | 3 |
| C | 3 |
| d | 3 |
| Ë | 4 |
| F | 4 |
| G | 3 |
| H | 3 |
| 一世 | 3 |
| Ĵ | 3 |
| 意思 | 3.2 |
| 标准。呃 | 0.13 |
摘要
许多研究人员无法理解标准偏差和标准误差之间的区别,即使它们通常包含在数据分析中。虽然标准偏差和标准误差的实际计算看起来非常相似,但它们代表两种非常不同但互补的措施。 SD告诉我们分布的形状,各个数据值与平均值的接近程度。 SE告诉我们我们的样本平均值与总人口的真实平均值有多接近。它们共同帮助提供比单独使用的平均值更全面的图像。


